
✍️Recommendation systems with Apache Spark🤔
data: Amazon product data
techniques: big data, collaborative filtering, ALS, Spark
Spring has sprung in NYC and it’s time for gardening! But how to buy the right hose when you’re a total gardening newbie?
This is a short step-by-step tutorial on collaborative filtering based recommendation systems on Amazon product data. Detailed instructions are included in the Jupyter Notebook on my github, so please check it out. Below, I included materials I found super useful to learn about recommendation systems & Apache Spark (which is used to paralelize alternative least squares at the end of the notebook).
For instructional purposes, the code is not optimized for speed.
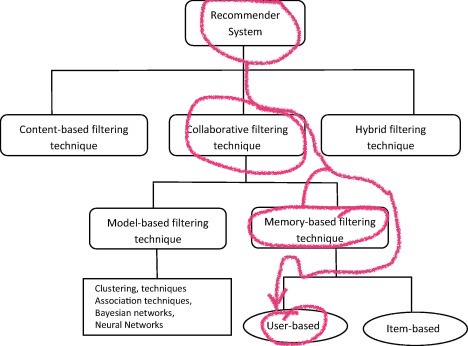
Source of the image (I added scribbles myself;): “Recommendation systems: Principles, methods and evaluation” by Isinkayea, Folajimib and Ojokohc, http://doi.org/10.1016/j.eij.2015.06.005
Resources:
Data:
Amazon’s data set contains reviews and metadata spanning from 1996 to 2014 and is an excellent source if you want to practice recommendation algorithms. As you might suspect, it’s huge, but Julian McAuley from UCSD also shared smaller subsets. I decided to use one of the 5-core datasets which contain entries from users who reviewed at least 5 products and products which were reviewed at least 5 times, which drastically limits the size of it allowing to run costly algorithms (such as ALS) on a personal laptop within a reasonable time (it took me few minutes).
Readings:
Blog posts about collaborative filtering and Alternative Least Squares:
Andrew Ng’s awesome intro to recommender systems (part of his ML coursera series, so pretty basic)
Ethan Rosenthal’s excellent blog post about collaborative filtering and matrix factorization (a bit more advanced).
Alex Abate on collaborative filtering - I heavily borrowed from her prediction rating code, which demonstrates step-by-step how it works.
bugra on Alternating Least Squares.
Apache Spark
Using Apache Spark makes a lot of sense when we’re using iterative algorithms (such as gradient descent or alternative least squares) as it leverages its capacity for caching / persisting (taking a snapshot of the data and iterating only over steps which are unique across iterations).
Running Apache Spark with Jupyter Notebook:
It’s not hard at all, actually! Make sure SSH is enabled on your machine, your Java is up to date, and download + install Spark. In my case, in order to run it I need to execute in the Terminal:
$ export PATH=$PATH:/usr/local/spark/bin:/usr/local/spark/sbin
followed by:
$ start-all.sh
and to lanch Jupyter Notebook with Spark:
$ PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook --no-browser --ip="*"" pyspark --master local[*]
Then, Jupyter Notebook will run on localhost:8888, your Spark cluster UI on localhost:8080 and Spark Jobs on localhost:4040.
Those tips come from Austin Ouyang who wrote a great step-by-step intro and gave a two day workshop at Insight Labs that I attended (and you can sign up for too:).
To see how to run ALS on Spark using Python, proceed to Jupyter Notebook on my github.
Machine learning and collaborative filtering with Spark:
Spark mllib docs on collaborative filtering
A great tutorial on recommendations systems and Spark with MovieLens data
Requirements:
To install all of them (except Python) using pip run:
pip install -r requirements.txt